Optimizing Performance¶
Tip
Before getting started, it is always important to measure the performance. Consider using the Grafana dashboard templates as described in Monitoring.
Introduction¶
There are some base design attributes and assumptions that FlytePropeller applies:
Every workflow execution is independent and can be performed by a completeley distinct process.
When a workflow definition is compiled, the resulting DAG structure is traversed by the controller and the goal is to gracefully transition each task to
Success.Task executions are performed by various FlytePlugins; which perform operations on Kubernetes and other remote services as declared in the workflow definition. FlytePropeller is only responsible for effectively monitoring and managing these executions.
In the following sections you will learn how Flyte ensures the correct and reliable execution of workflows through multiple stages, and what strategies you can apply to help the system efficiently handle increasing load.
Summarized steps of a workflow execution¶
Let’s revisit the lifecycle of a workflow execution. The following diagram aims to summarize the process described in the FlytePropeller Architecture and Timeline of a workflow execution sections, focusing on the main steps.
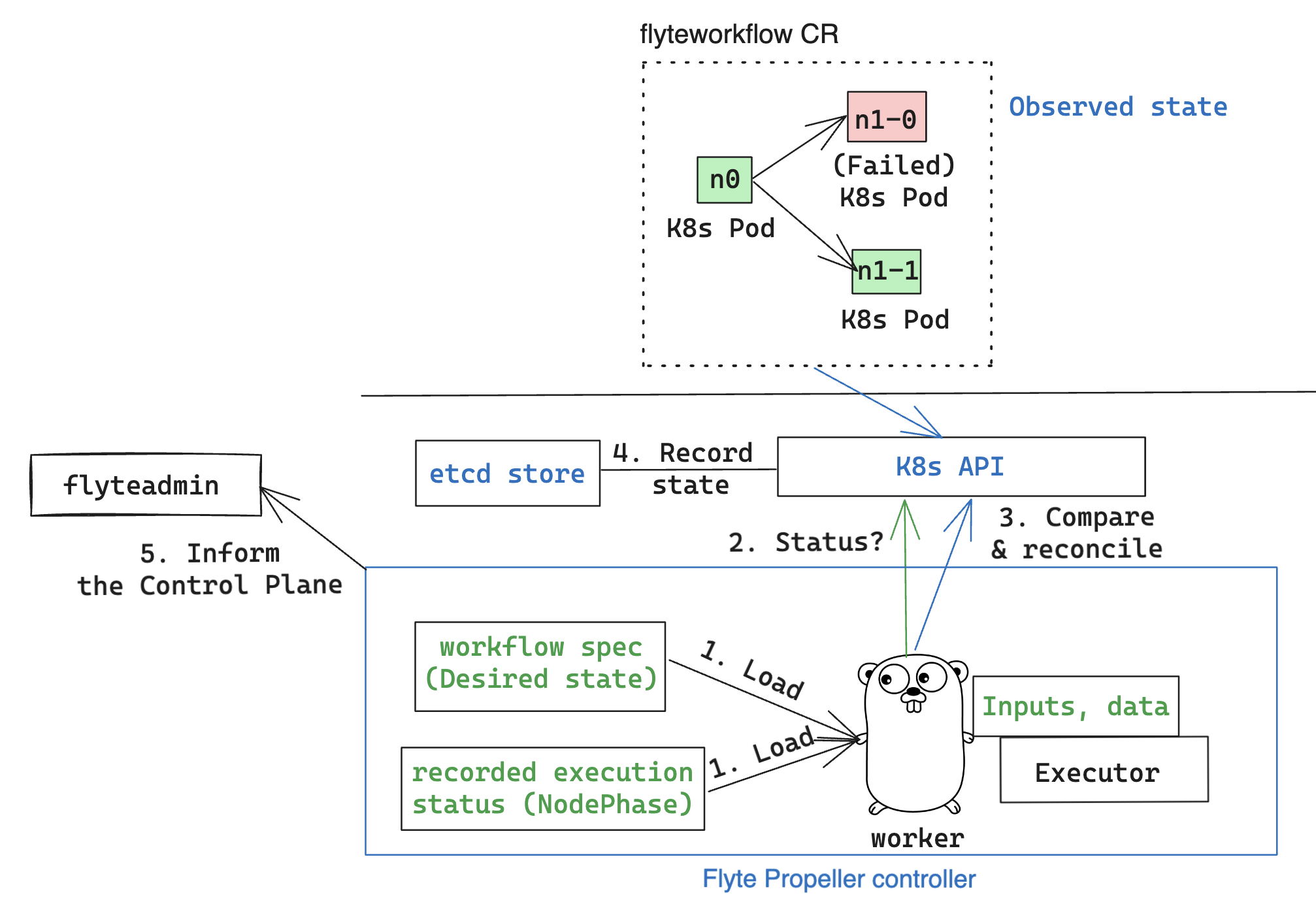
The Worker is the independent, lightweight, and idempotent process that interacts with all the components in the Propeller controller to drive executions.
It’s implemented as a goroutine, and illustrated here as a hard-working gopher which:
Pulls from the
WorkQueueand loads what it needs to do the job: the workflow specification (desired state) and the previously recorded execution status.Observes the actual state by querying the Kubernetes API (or the Informer cache).
Calculates the difference between desired and observed state, and triggers an effect to reconcile both states (eg. Launch/kill a Pod, handle failures, schedule a node execution, etc), interacting with the Propeller executors to process inputs, outputs and offloaded data as indicated in the workflow spec.
Keeps a local copy of the execution status, besides what the K8s API stores in
etcd.Reports status to the control plane and, hence, to the user.
This process is known as the “evaluation loop”.
While there are multiple metrics that could indicate a slow down in execution performance, round_latency -or the time it takes FlytePropeller to complete a single evaluation loop- is typically the “golden signal”.
Optimizing round_latency is one of the main goals of the recommendations provided in the following sections.
Performance tuning at each stage¶
1. Workers, the WorkQueue, and the evaluation loop¶
Property |
Description |
Relevant metric |
Impact on performance |
Configuration parameter |
|---|---|---|---|---|
|
Number of processes that can work concurrently. Also implies number of workflows that can be executed in parallel. Since FlytePropeller uses |
|
A low number may result in higher overall latency for each workflow evaluation loop, while a higher number implies that more workflows can be evaluated in parallel, reducing latency. The number of workers depends on the number of CPU cores assigned to the FlytePropeller pod, and should be evaluated against the cost of context switching. A number around 500 - 800 workers with 4-8 CPU cores is usually adequate. |
|
Workqueue depth |
Current number of workflow IDs in the queue awaiting processing |
|
A growing trend indicates the processing queue depth is long and is taking longer to drain, delaying start time for executions. |
|
2. Query observed state¶
The Kube client config controls the request throughput from FlytePropeller to the Kube API server. These requests may include creating/monitoring pods or creating/updating FlyteWorkflow CRDs to track workflow execution.
The default configuration provided by K8s results in very conservative rate-limiting. FlytePropeller provides a default configuration that may offer better performance.
However, if your workload involves larger scales (e.g., >5k fanout dynamic or map tasks, >8k concurrent workflows, etc.,) the kube-client rate limiting config provided by FlytePropeller may still contribute to a noticeable drop in performance.
Increasing the qps and burst values may help alleviate back pressure and improve FlytePropeller performance. The following is an example kube-client config applied to Propeller:
propeller:
kube-client-config:
qps: 100 # Refers to max rate of requests (queries per second) to kube-apiserver
burst: 120 # refers to max burst rate.
timeout: 30s # Refers to timeout when talking with the kube-apiserver
Note
In the previous example, the kube-apiserver will accept 100 queries per second, temporariliy admitting up to 120 before blocking any subsequent query. A query blocked for 30s will timeout.
It is worth noting that the Kube API server tends to throttle requests transparently. This means that even after increasing the allowed frequency of API requests (e.g., increasing FlytePropeller workers or relaxing Kube client config rate-limiting), there may be steep performance decreases for no apparent reason.
While it’s possible to easily monitor Kube API saturation using system-level metrics like CPU, memory, and network usage, we recommend looking at kube-apiserver-specific metrics like workqueue_depth which can assist in identifying whether throttling is to blame. Unfortunately, there is no one-size-fits-all solution here, and customizing these parameters for your workload will require trial and error.
Learn more about Kubernetes metrics
3. Evaluate the DAG and reconcile state as needed¶
Property |
Description |
Impact on performance |
Configuration parameter |
|---|---|---|---|
|
Interval at which the system re-evaluates the state of a workflow when no external events have triggered a state change. This periodic re-evaluation helps in progressing workflows that may be waiting on conditions or timeouts to be met. |
A shorter duration means workflows are checked more frequently, which can lead to quicker progression through workflow steps but at the cost of increased load on the system. Conversely, a longer duration reduces system load but may delay the progression of workflows. |
|
|
Interval at which the system checks for updates on the execution status of downstream tasks within a workflow. This setting is crucial for workflows where tasks are interdependent, as it determines how quickly Flyte reacts to changes or completions of tasks that other tasks depend on. |
A shorter interval makes Flyte check more frequently for task updates, which can lead to quicker workflow progression if tasks complete faster than anticipated, at the cost of higher system load and reduced throughput. Conversely, a higher value reduces the frequency of checks, which can decrease system load but may delay the progression of workflows, as the system reacts slower to task completions. |
|
|
Maximum number of consecutive evaluation rounds that one propeller worker can use for one workflow. |
A large value can lead to faster completion times for workflows that benefit from continuous processing, especially cached or computationally intensive workflows, but at the cost of lower throughput and higher latency as workers will spend most of their time on a few workflows. If set to |
|
|
Max size of the write-through in-memory cache that FlytePropeller can use to store Inputs/Outputs metadata for faster read operations. |
A too-small cache might lead to frequent cache misses, reducing the effectiveness of the cache and increasing latency. Conversely, a too-large cache might consume too much memory, potentially affecting the performance of other components. We recommend monitoring cache performance metrics such as hit rates and miss rates. These metrics can help determine if the cache size needs to be adjusted for optimal performance. |
|
|
Maximum back-off interval in case of resource-quota errors. |
A higher value will ensure retries do not happen too frequently, which could overwhelm resources or overload the Kubernetes API server at the cost of overall latency. |
|
4. Record execution status¶
Property |
Description |
Impact on performance |
Configuration parameter |
|---|---|---|---|
|
Specifies the strategy for workflow storage management. |
The default policy is designed to leverage |
|
How ``ResourceVersionCache`` works?
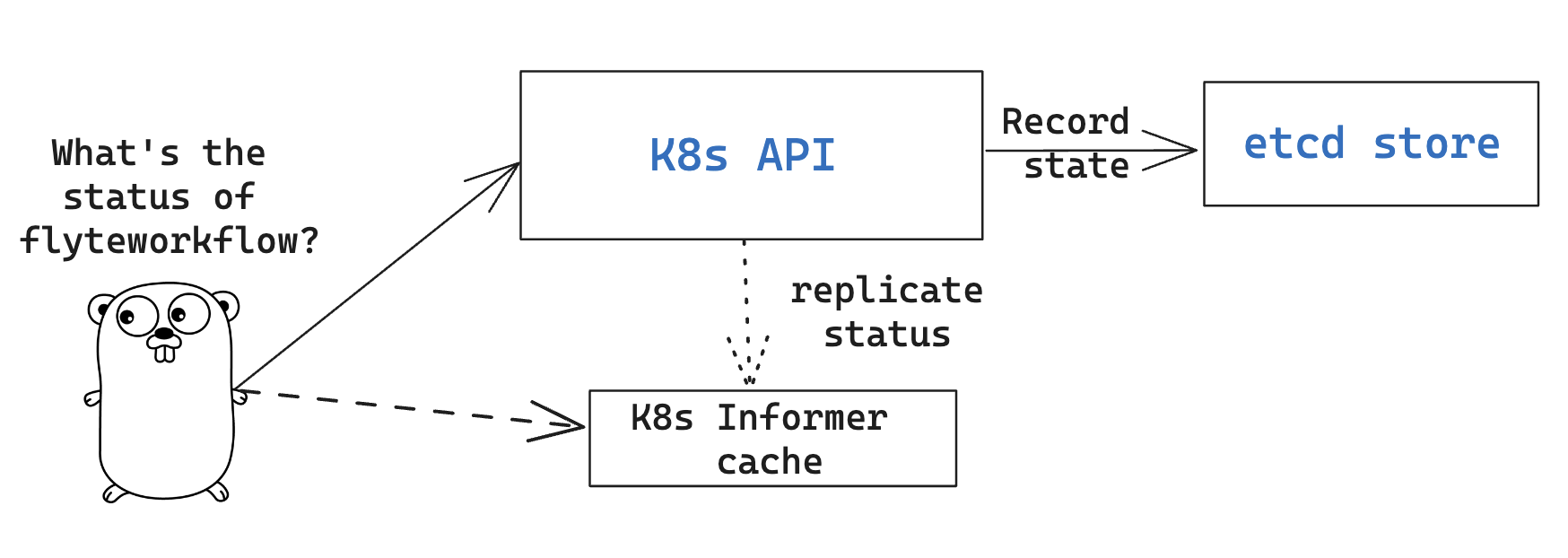
Kubernetes stores the definition and state of all the resources under its management on etcd: a fast, distributed and consistent key-value store.
Every resource has a resourceVersion field representing the version of that resource as stored in etcd.
Example:
kubectl get datacatalog-589586b67f-l6v58 -n flyte -o yaml
Sample output (excerpt):
apiVersion: v1
kind: Pod
metadata:
...
labels:
app.kubernetes.io/instance: flyte-core
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/name: datacatalog
helm.sh/chart: flyte-core-v1.12.0
name: datacatalog-589586b67f-l6v58
namespace: flyte
...
resourceVersion: "1055227"
Every time a resource (e.g. a pod, a flyteworkflow CR, etc.) is modified, this counter is incremented.
As etcd is a distributed key-value store, it needs to manage writes from multiple clients (controllers in this case)
in a way that maintains consistency and performance.
That’s why, in addition to using Revisions (implemented in Kubernetes as Resource Version), etcd also prevents clients from writing if they’re using
an outdated ResourceVersion, which could happen after a temporary client disconnection or whenever a status replication from the Kubernetes API to
the Informer cache hasn’t completed yet. Poorly handled by a controller, this could result in kube-server and FlytePropeller worker overload by repeatedly attempting to perform outdated (or “stale”) writes.
FlytePropeller handles these situations by keeping a record of the last known ResourceVersion. In the event that etcd denies a write operation due to an outdated version, FlytePropeller continues the workflow
evaluation loop, waiting for the Informer cache to become consistent. This mechanism, enabled by default and known as ResourceVersionCache, avoids both overloading the K8s API and wasting workers resources on invalid operations.
It also mitigates the impact of cache propagation latency, which can be on the order of seconds.
If max-streak-length is enabled, instead of waiting for the Informer cache to become consistent during the evaluation loop, FlytePropeller runs multiple evaluation loops using its in-memory copy of the ResourceVersion and corresponding Resource state, as long
as there are mutations in any of the resources associated with that particular workflow. When the max-streak-length limit is reached, the evaluation loop is done and, if further evaluation is required, the cycle will start again by trying to get the most recent Resource Version as stored in etcd.
Other supported options for workflowStore.policy are described below:
InMemory: utilizes an in-memory store for workflows, primarily for testing purposes.PassThrough: directly interacts with the underlying Kubernetes clientset or shared informer cache for workflow operations.TrackTerminated: specifically tracks terminated workflows.
5. Report status to the control plane¶
Property |
Description |
Impact on performance |
|---|---|---|
|
Configure the maximum rate and number of launchplans that FlytePropeller can launch against FlyteAdmin. |
It is important to limit the number of writes from FlytePropeller to FlyteAdmin to prevent brown-outs or request throttling at the server. Also a bigger cache size, reduces number of calls to the server. |
Concurrency vs parallelism¶
While FlytePropeller is designed to efficiently handle concurrency using the mechanisms described in this section, parallel executions (not only concurrent, but evaluated at the same time) pose an additional challenge, especially with workflows that have an extremely large fan-out.
This is because FlytePropeller implements a greedy traversal algorithm, that tries to evaluate all unblocked nodes within a workflow in every round.
A way to mitigate the potential performance impact is to limit the maximum number of nodes that can be evaluated simultaneously. This can be done by setting max-parallelism using any of the following methods:
Platform default: This allows to set platform-wide defaults for maximum parallelism within a Workflow execution evaluation loop. This can be overridden per launch plan or per execution. The default maxParallelism is configured to be 25. It can be overridden with this config block in flyteadmin
flyteadmin: maxParallelism: 25
Default for a specific launch plan. For any launch plan, the
max_parallelismvalue can be changed usingflytekit.LaunchPlan.get_or_create()or the LaunchPlanCreateRequest Flytekit ExampleLaunchPlan.get_or_create( name="my_cron_scheduled_lp", workflow=date_formatter_wf, max_parallelism=30, )
Specify for an execution.
max-parallelismcan be overridden usingpyflyte run --max-parallelismor by setting it in the UI.
Scaling out FlyteAdmin¶
FlyteAdmin is a stateless service. Often, before needing to scale FlyteAdmin, you need to scale the backing database. Check the FlyteAdmin Dashboard for signs of database or API latency degradation. PostgreSQL scaling techniques like connection pooling can help alleviate pressure on the database instance. If needed, change the number of replicas of the FlyteAdmin K8s deployment to allow higher throughput.
Scaling out Datacatalog¶
Datacatalog is a stateless service that connects to the same database as FlyteAdmin, so the recommendation to scale out the backing PostgreSQL database also applies here.
Scaling out FlytePropeller¶
Multi-Cluster mode¶
If the K8s cluster itself becomes a performance bottleneck, Flyte supports adding multiple K8s dataplane clusters by default. Each dataplane cluster has one or more FlytePropellers running in it, and flyteadmin manages the routing and assigning of workloads to these clusters.
Improving etcd Performance¶
Offloading Static Workflow Information from CRD¶
Flyte uses a K8s CRD (Custom Resource Definition) to store and track workflow executions. This resource includes the workflow definition, the tasks and subworkflows that are involved, and the dependencies between nodes. It also includes the execution status of the workflow. The latter information (i.e. runtime status) is dynamic, and changes during the workflow’s execution as nodes transition phases and the workflow execution progresses. However, the former information (i.e. workflow definition) remains static, meaning it will never change and is only consulted to retrieve node definitions and workflow dependencies.
CRDs are stored within etcd, which requires a complete rewrite of the value data every time a single field changes. Consequently, the read / write performance of etcd, as with all key-value stores, is strongly correlated with the size of the data. In Flyte’s case, to guarantee only-once execution of nodes, we need to persist workflow state by updating the CRD at every node phase change. As the size of a workflow increases this means we are frequently rewriting a large CRD. In addition to poor read / write performance in etcd, these updates may be restricted by a hard limit on the overall CRD size.
To counter the challenges of large FlyteWorkflow CRDs, Flyte includes a configuration option to offload the static portions of the CRD (ie. workflow / task / subworkflow definitions and node dependencies) to the S3-compliant blobstore. This functionality can be enabled by setting the useOffloadedWorkflowClosure option to true in the FlyteAdmin configuration. When set, the FlyteWorkflow CRD will populate a WorkflowClosureReference field on the CRD with the location of the static data and FlytePropeller will read this information (through a cache) during each workflow evaluation. One important note is that currently this setting requires FlyteAdmin and FlytePropeller to have access to the same blobstore since FlyteAdmin only specifies a blobstore location in the CRD.